5 Crucial Facts About MemPrivacy: The Edge-Cloud Framework That Protects Private Data Without Sacrificing AI Memory Utility
As LLM-powered agents transition from research labs to real-world applications, a critical tension emerges: the more capable cloud-hosted memory becomes, the more sensitive user data it exposes. A joint effort by researchers from MemTensor (Shanghai), HONOR Device, and Tongji University introduces MemPrivacy, a framework that tackles this dilemma head-on. Instead of compromising either privacy or utility, it employs a clever technique called local reversible pseudonymization. Below, we break down the five essential facts you need to know about this innovative approach.
1. The Core Privacy Vulnerability in Cloud Memory
When you chat with an AI agent, your conversations often contain personal details—health conditions, email addresses, financial figures, passwords. In typical edge-cloud setups, your device handles input while the cloud manages memory and reasoning. This efficient architecture unfortunately sends raw user data to cloud systems, where it persists in logs, vector databases, and external stores. The risk is real: studies show multi-turn memory attacks succeed up to 69% of the time, and leakage attacks hit 75% success rates. Even indirect prompt injection can trick agents into extracting private information. Once data enters cloud storage, it remains accessible long after the original interaction, creating a persistent exposure that prior privacy methods struggle to address.
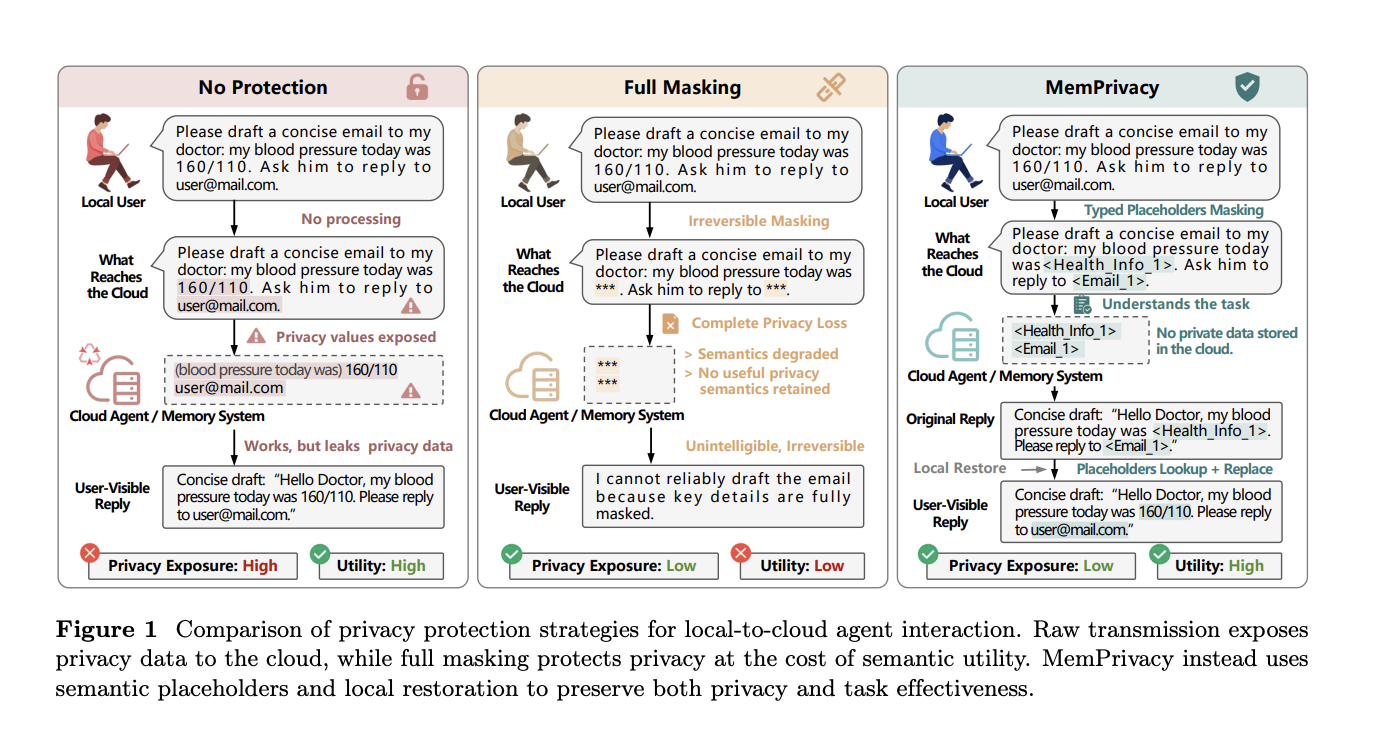
2. Why Traditional Privacy Methods Fall Short
Earlier attempts to protect user data typically relied on masking—replacing sensitive values with placeholders like ***. While simple, this approach destroys semantic meaning. If a user asks an agent to draft a doctor's email and both a blood pressure reading and an email address are masked, the cloud model cannot complete the task meaningfully. More advanced techniques like differential privacy and cryptographic protection offer stronger guarantees but are notoriously difficult to integrate into interactive memory pipelines without degrading response quality. These methods often require complex computations or reduce the model's ability to use context, leading to robotic or incomplete answers. The gap between security and usability remains wide—until now.
3. How MemPrivacy's Local Reversible Pseudonymization Works
Instead of masking or encrypting data, MemPrivacy replaces sensitive spans with typed placeholders—structured tokens like <Health_Info_1> or <Email_1>—before leaving the local device. The cloud model receives semantically intact text and can reason and store memories normally; it just never sees the actual values. When the cloud returns a response containing placeholders, the device looks up the originals from a secure local database and substitutes them back. The user sees a fully coherent, personalized response. This design, called local reversible pseudonymization, preserves utility while keeping sensitive data under user control. The entire process happens transparently, with no perceptible latency or loss of functionality.
4. The Three-Stage Pipeline: From Desensitization to Reconstruction
The framework operates in three distinct stages. Stage 1 (Uplink Desensitization): A lightweight on-device model identifies privacy-sensitive spans in the input, classifies each by type and sensitivity level, and replaces them with typed placeholders. The original-to-placeholder mappings are stored locally and persist throughout the session. Stage 2 (Cloud Processing): The cloud receives the desensitized text and processes it normally—retrieving memories, reasoning, generating responses. It may store the placeholder data in its vector databases or logs without ever exposing the real values. Stage 3 (Downlink Reconstruction): When the cloud returns a response containing placeholders, the local device retrieves the original values from its secure store and substitutes them back. The user gets a seamless, private interaction without any extra steps.
5. Why This Matters for the Future of AI Assistants
MemPrivacy addresses a fundamental barrier to trust in AI agents. By keeping sensitive data on the device while still enabling powerful cloud-based memory and reasoning, it paves the way for more widespread adoption of personalized assistants in sensitive domains like healthcare, finance, and legal services. The framework is lightweight enough to run on consumer devices without draining battery or processing power, as the on-device model is specifically optimized for classification tasks. Moreover, its modular design allows for easy integration with existing edge-cloud architectures. As privacy regulations tighten and user awareness grows, solutions like MemPrivacy will become not just useful but essential for any agent that handles personal information.
Conclusion: MemPrivacy proves that you don't have to choose between privacy and utility. By cleverly anonymizing data at the edge and reconstructing it locally, it keeps sensitive information safe without breaking the functionality that makes AI helpful. As LLM-powered agents become ubiquitous, frameworks like this will be key to building systems that users can truly trust.
Related Articles
- 7 Key Facts About Chrome's Mysterious weights.bin File (And What Google Says)
- Mastering Samsung’s One UI 9 Beta: A Complete Guide to Android 17 on Galaxy Devices
- Python 3.14.3: What You Need to Know About the Latest Maintenance Release
- From Traditional to Digital: How Western Union Launched USDPT on Solana
- Legacy UX Crisis: Enterprises Waste 60% of Time Managing Broken Systems, Experts Warn
- How to Vibe-Code Your Own Widgets with Google's Create My Widget Feature
- Kubernetes 1.36: Volume Group Snapshots Now Generally Available
- Saros Final Boss Strategy Revealed: Mastering Defensive Skills Key to Victory